Les lecteurs de Vikidia demandent des articles en plus. Voyez la liste d'articles à créer, et venez nous aider à les rédiger !
Apprentissage automatique
En informatique, et plus précisément dans le domaine de l'intelligence artificielle, l'apprentissage automatique est le champ d'étude de l'ensemble de méthodes et algorithmes permettant à un programme d'apprendre par lui-même, à l'aide de données fournies, sans être explicitement programmé pour accomplir cette tâche à la base. Le terme anglais machine learning est aussi souvent utilisé pour se référer à ce domaine de recherche.
L'apprentissage automatique permet d'apprendre des choses à un programme que nous ne savons pas comment programmer explicitement. Cela permet d'apprendre aux systèmes informatique à comprendre, analyser et interagir avec les données de notre monde tel que des images ou du texte par exemple.
Terminologie[modifier | modifier le wikicode]
Le terme modèle dans le contexte de l'apprentissage automatique désigne une représentation mathématique des données que l'on cherche à apprendre. Cette représentation a une structure définie, souvent une fonction mathématique, et des paramètres vont permettre de décrire le modèle mathématiquement. Ce sont ces paramètres qui sont optimisés afin de représenter au mieux nos données. Cette définition sonne très abstraite, mais on peut se représenter un modèle comme une simplification approximative des données. Des images telles que la deuxième à la fin de cette section aident également à comprendre mieux le concept.
L'ensemble des données est référé sous le terme jeu de données. Un jeu de données est constitué d'une série d'exemples. Un exemple peut être un texte, une image, une ligne dans un tableau de valeurs ou bien d'autres choses encore. À l'image d'un humain qui apprendra à faire des additions en faisant plein d'exemples de calculs d'additions, l'apprentissage automatique se fait également avec une série d'exemples qui permettront au modèle d'assimiler les connaissances souhaitées.
Chaque exemple est constitué de plusieurs attributs dont les valeurs peuvent être catégoriques ![]() ou bien continues
ou bien continues ![]() . La première image à la fin de cette section montre les attributs présents dans un jeu de données connu nommé Iris de Fisher1. Il est intéressant de noter que les attributs des données ne sont pas forcément interprétables pour un humain, elles n'auront pas nécessairement une signification intuitive pour nous. Dans une image par exemple, chaque valeur RGB de chaque pixel peut être un attribut, ainsi que la position du pixel par rapport aux autres pixels, même si un humain ne verrait aucun intérêt à décomposer des données ainsi et interpréterait l'image plutôt dans son ensemble ou par zones. Il est normal que les attributs n'aient pas toujours de sens logique pour un humain, car un ordinateur ne traite pas les informations de la même manière qu'un humain, et peut souvent extraire des informations intéressantes de données qui ne parlent pas aux humains. C'est un autre avantage que présente l'apprentissage automatique.
. La première image à la fin de cette section montre les attributs présents dans un jeu de données connu nommé Iris de Fisher1. Il est intéressant de noter que les attributs des données ne sont pas forcément interprétables pour un humain, elles n'auront pas nécessairement une signification intuitive pour nous. Dans une image par exemple, chaque valeur RGB de chaque pixel peut être un attribut, ainsi que la position du pixel par rapport aux autres pixels, même si un humain ne verrait aucun intérêt à décomposer des données ainsi et interpréterait l'image plutôt dans son ensemble ou par zones. Il est normal que les attributs n'aient pas toujours de sens logique pour un humain, car un ordinateur ne traite pas les informations de la même manière qu'un humain, et peut souvent extraire des informations intéressantes de données qui ne parlent pas aux humains. C'est un autre avantage que présente l'apprentissage automatique.
Chaque exemple peut posséder un label (ou une classe) qui est une catégorie ou une valeur numérique associée à cet exemple. C'est généralement ce label que l'on cherche à prédire avec l'apprentissage automatique. Dans la première image ci-dessous, la couleur du point indique le label associé à l'exemple. Théoriquement, n'importe quel attribut des données peut être un label, et les jeux de données contiennent souvent plusieurs attributs pouvant servir de label. Par exemple, dans la deuxième image ci-dessous, on peut utiliser la taille et le sexe pour prédire le poids, ou bien utiliser la taille et le poids pour prédire le sexe.

Le jeu de données Iris de Fisher1 contient un ensemble d'exemples de fleurs iris. Ces exemples sont définis par les attributs "longueur de sépale", "largeur de sépale", "longueur des pétales" et "largeur des pétales". Les valeurs de ces attributs sont représentées dans cette image par des nuages de points. Les couleurs des points correspondent au label de l'exemple, il y a donc 3 classes de fleurs iris représentées dans ce jeu de données.

Un exemple simple de régression linéaire, qui est un type de modèle. Chaque petite croix représente un exemple2, dont la valeur de l'axe horizontale est le poids et la valeur de l'axe verticale la taille. Les croix vertes correspondent à des exemples d'hommes et les magenta de femmes. Il y a 2 modèles dans l'image: l'un, qui est la ligne verte, est obtenu à partir les exemples d'hommes (croix vertes), et l'autre, la ligne en magenta, avec les exemples de femmes. On voit bien ici que la ligne verte est une approximation des données représentées par les croix vertes, et il en va de même pour les magenta.


Histoire[modifier | modifier le wikicode]
Types de tâches[modifier | modifier le wikicode]

L'apprentissage automatique permet d'accomplir une grande variété de tâches différentes. Certaines de ces tâches servent à l'analyse des données, utilisée beaucoup dans le domaine de la science des données, entre autres pour déterminer les relations entre les attributs des données et trouver des correlations ![]() importantes. D'autres visent à prédire quelque chose, tel que la catégorie à laquelle appartient un nouvel exemple que l'on donne au modèle. Par exemple, un système de recommandation doit déterminer quels utilisateurs aimeront un nouveau produit sur base des informations qu'il a sur les préférences des utilisateurs. Plus récemment, la recherche s'est également orientée vers des modèles permettant la génération de nouvelles données. Un exemple d'application est un chatbot, qui va devoir générer du texte pour communiquer avec les humains. Un autre exemple connu est thispersondoesnotexist3, qui génère des images d'humains très réalistes mais qui n'existent pas réellement, et des modèles tels que celui-ci permettent par exemple de générer des données pour l'entrainement de modèles beaucoup plus facilement que par la collecte traditionnelle de données45.
importantes. D'autres visent à prédire quelque chose, tel que la catégorie à laquelle appartient un nouvel exemple que l'on donne au modèle. Par exemple, un système de recommandation doit déterminer quels utilisateurs aimeront un nouveau produit sur base des informations qu'il a sur les préférences des utilisateurs. Plus récemment, la recherche s'est également orientée vers des modèles permettant la génération de nouvelles données. Un exemple d'application est un chatbot, qui va devoir générer du texte pour communiquer avec les humains. Un autre exemple connu est thispersondoesnotexist3, qui génère des images d'humains très réalistes mais qui n'existent pas réellement, et des modèles tels que celui-ci permettent par exemple de générer des données pour l'entrainement de modèles beaucoup plus facilement que par la collecte traditionnelle de données45.
Selon le type de tâche, certains types de modèles seront plus appropriés que d'autres, mais le principe derrière l'apprentissage automatique reste le même.
Types d'apprentissage et modèles[modifier | modifier le wikicode]
Apprentissage supervisé[modifier | modifier le wikicode]
L'apprentissage supervisé utilise des données dont les exemples possèdent des labels pour apprendre. L'idée est que l'algorithme apprend à reconnaitre les caractéristiques correspondant à chacun des labels, afin de pouvoir ensuite prédire le label de données inconnues en se basant sur les caractéristiques de ces données.
Il existe deux catégories de tâches en apprentissage supervisé: les régressions et les classifications6. Une régression permet de prédire un label continu, typiquement une valeur (par exemple une note, une température, une probabilité ou encore autre chose, tout dépend de la tâche du modèle). Une classification permet de prédire un label discret (par exemple un âge en années, ou bien « cancer » ou « pas cancer » ou encore autre chose, ici aussi ça dépend de la tâche).
Le modèle le plus populaire pour faire une régression est la régression linéaire. Pour la classification, la régression logistique et les machine à vecteurs de support sont des modèles populaires. Il y a également un nombre notable de modèles populaires qui peuvent être utilisés pour les deux catégories de tâches, par exemple les arbres de décision et les réseau de neurones artificiels.

Une régression linéaire.

Une machine à vecteurs de support.

Un réseau de neurones très simple.



Apprentissage non-supervisé[modifier | modifier le wikicode]
Apprentissage par renforcement[modifier | modifier le wikicode]






Au lieu d'apprendre avec les données directement comme c'est le cas en apprentissage supervisé et non-supervisé, l'apprentissage par renforcement fonctionne avec un système de récompenses et punitions. Il est souvent étudié et utilisé dans les disciplines telles que la théorie des jeux, parce que les méchanismes utilisés dans l'apprentissage par renforcement ressemblent à des jeux.
Dans l'apprentissage par renforcement, on a un agent qui cherche à accumuler un maximum de récompenses, par exemple des points. Cet agent est dans un environnement qu'il ne connait pas mais qu'il peut explorer à l'aide d'une série d'actions. Les actions qu'un agent peut choisir de faire sont déterminées selon l'état actuel de l'agent. Par exemple, si l'agent est face à un mur, il ne peut pas avancer, mais il peut se retourner. Si l'agent n'a aucun obstacle devant lui, il peut choisir d'avancer ou bien se retourner. Son but est de trouver les meilleures actions à effectuer afin de maximiser sa récompense. En explorant son environnement, l'agent peut par exemple découvrir que se déplacer vers un trésor lui rapporterai beaucoup de points, mais que marcher dans un piège lui fera perdre des points, et il apprendra à trouver les trésors en évitant les pièges.
Un modèle d'apprentissage par renforcement est généralement décrit par ce qu'on appelle un processus de décision markovien. Pour faire très simple, c'est un ensemble d'états dans lesquels l'agent peut se trouver, liés par des probabilités de transition d'un état à l'autre qui dépendent de l'action sélectionnée par l'agent ainsi qu'une part aléatoire. Par exemple, un agent qui a une balle de basket en main et se trouve dans l'état « loin du panier » peut choisir l'action « dribbler avec la balle » afin de tenter d'atteindre l'état « proche du panier ». Si l'agent fait ce choix, il a une probabilité de réussir son mouvement et d'effectivement atteindre l'état « proche du panier », mais il a également le risque de se faire bloquer par un adversaire, ce qui le ferait rester à l'état « loin du panier ». Si depuis l'état « loin du panier », l'agent décide de choisir une autre action, par exemple « tirer vers le panier » pour directement essayer de marquer, il a une probabilité élevée de rater son tir et risque de ne pas gagner de point, mais il a quand même une chance de le réussir, ce qui lui ferait gagner un point, donc augmenterait sa récompense. L'apprentissage par renforcement vise à déterminer pour chaque état dans lequel peut se trouver l'agent quelle est la meilleure action à faire afin de gagner le plus de récompense possible.
Le processus d'apprentissage[modifier | modifier le wikicode]
L'objectif de l'apprentissage automatique est de trouver une bonne représentation mathématique, qui expliquera donc bien les données que nous avons.
Afin qu'un programme puisse interpréter et apprendre des données, il est d'abord nécessaire de nettoyer et d'exprimer ces données d'une manière exploitable par un algorithme d'optimisation. Ensuite, on initialise un modèle mathématique dont les paramètres sont aléatoires au départ. Puis, pour que notre modèle puisse représenter nos données, on l'entraine sur nos données avec un algorithme d'optimisation pour améliorer les valeurs des paramètres. Le modèle entrainé est le résultat final de cet apprentissage et l'évaluer permet de déterminer à quel point il remplit bien la tâche pour laquelle il a été entrainé.
Il est intéressant de noter ici que l'apprentissage automatique suppose toujours qu'il existe une représentation mathématique expliquant bien nos données, mais ce n'est pas toujours le cas. Notamment, lorsque les attributs des données ne présentent aucune correlation avec leurs labels (ce sera typiquement le cas si les attributs utilisés sont inadéquats pour la tâche ciblée), la représentation mathématique résultante sera très mauvaise car une bonne représentation n'existe simplement pas.
Prétraitement des données[modifier | modifier le wikicode]
La phase de prétraitement des données comporte en premier lieu la tâche de nettoyage des données. Le nettoyage des données consiste principalement à réparer d'éventuelles erreurs dans les données, compléter les valeurs manquantes et retirer les exemples qu'on appelle des données aberrantes. Ces exemples sont des anomalies dans les données, et peuvent rendre le modèle beaucoup moins bon, car il va apprendre avec des exemples qui représentent des exceptions et non la généralité. S'ils sont identifiables, il faut donc les retirer afin d'éviter ces problèmes.
Bien que ce ne soit pas nécessaire pour entrainer un modèle, il est également préférable de faire une analyse des données pour mieux comprendre ce avec quoi on travaille. Par exemple, si on travaille avec des photos de visages, mais que la majorité des gens sur les photos sont des personnes blanches, il faut s'attendre à ce que le modèle qu'on obtiendra fonctionne bien mieux avec des photos de personnes de peau blanche qu'avec des personnes de peau plus foncée.
Une fois les données analysées et nettoyées, il faut exprimer les données dans un format exploitable par les algorithmes d'optimisation utilisés dans l'apprentissage automatique. Bien que les données numérisées soient déjà exprimées dans un langage interprétable par un ordinateur, elles sont rarement dans un format adéquat de base. Il faudra donc souvent les traiter par des procédés mathématiques comme la standardisation, mais certaines formes de données nécessitent également des traitements plus spécifiques. C'est notamment le cas du texte, car chaque mot doit être représenté par un nombre tout en gardant son sens par rapport à son contexte.
Optimisation[modifier | modifier le wikicode]
Une fois les données prétraitées, elles sont exploitables par un procédé mathématique d'optimisation. Cette optimisation se fait en minimisant ![]() une fonction particulière que l'on appelle la fonction objectif. Pour minimiser cette fonction, l'algorithme le plus souvent utilisé est l'algorithme du gradient.
une fonction particulière que l'on appelle la fonction objectif. Pour minimiser cette fonction, l'algorithme le plus souvent utilisé est l'algorithme du gradient.
Note: Il existe certain types de modèles qui ne nécessitent aucune optimisation, c'est par exemple le cas de la méthode des k plus proches voisins (souvent abrégée KNN). Cette section présente la méthode qui est de très loin la plus répandue d'optimiser des modèles qui nécessitent cette étape optimisation, par exemple les réseaux de neurones artificiels.
Fonction objectif[modifier | modifier le wikicode]

Lorsqu'on donne les attributs d'un exemple au modèle, il renvoie une prédiction. On peut mesurer l'écart entre la prédiction et le véritable label de l'exemple comme illustré sur l'image à droite, et cet écart est appelé l'erreur. Lorsqu'on modifie les valeurs des paramètres du modèle, on va également modifier la prédiction du modèle, ce qui va donc modifier l'erreur. On peut représenter l'erreur sur un graphe dont les axes sont les valeurs des paramètres et la valeur de l'erreur. La fonction qu'on obtient est appelée fonction objectif. Donc, la fonction objectif est la fonction qui représente l'erreur en fonction des paramètres du modèle.
Comme on cherche les paramètres du modèle qui représenteront au mieux nos données, on souhaite naturellement que la somme des erreurs sur les exemples de nos données soit la plus petite possible. C'est la raison pour laquelle on cherche à minimiser la fonction objectif; en trouvant les paramètres qui minimisent la fonction objectif, on trouve les meilleurs paramètres pour notre modèle.

Un exemple de fonction objectif. Les axes x et y sont les paramètres du modèle et l'axe verticale est la somme des erreurs sur les données. On voit que les meilleurs paramètres pour ce modèle seraient (0, 0).
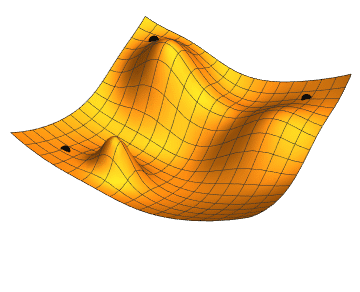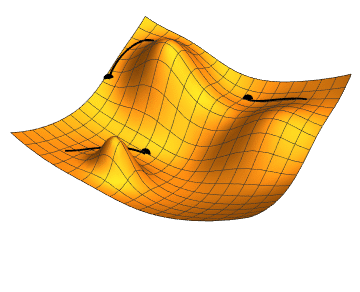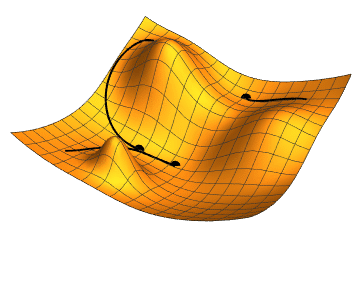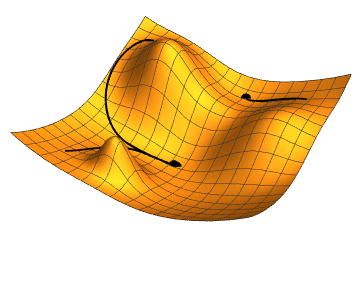
Un deuxième exemple de fonction objectif. Ici, la forme obtenue est plus compliquée et a plusieurs minimums. Toutes les optimisations ne donneront pas le même résultat en fonction du point de départ, donnant des modèles avec des performances différentes.


La forme générale de cette fonction variera selon le type de modèle utilisé, mais aussi selon la manière de calculer l'erreur. Par exemple, on peut décider de travailler avec les valeurs absolues ![]() des erreurs, afin d'éviter que des erreurs très positives et très négatives ne s'annulent lorsqu'on les aditionne. Ou bien, on peut utiliser le carré
des erreurs, afin d'éviter que des erreurs très positives et très négatives ne s'annulent lorsqu'on les aditionne. Ou bien, on peut utiliser le carré ![]() des erreurs, qui lui aussi donnera des valeurs uniquement positives, mais qui seront proportionnellement beaucoup plus grandes pour de grandes erreurs que pour de petites erreurs. Utiliser le carré au lieu de la valeur absolue des erreurs rend le modèle plus sensible aux données aberrantes s'il en reste dans les données, car ces anomalies auront une grande erreur par rapport à la prédiction du modèle.
des erreurs, qui lui aussi donnera des valeurs uniquement positives, mais qui seront proportionnellement beaucoup plus grandes pour de grandes erreurs que pour de petites erreurs. Utiliser le carré au lieu de la valeur absolue des erreurs rend le modèle plus sensible aux données aberrantes s'il en reste dans les données, car ces anomalies auront une grande erreur par rapport à la prédiction du modèle.
Minimisation de la fonction objectif[modifier | modifier le wikicode]
Comme décrit dans la section précédente, l'apprentissage automatique vise à minimiser la fonction objectif afin de trouver le modèle qui représente les données avec le moins d'erreur possible. Il suffit donc de tracer la fonction objectif afin de trouver les paramètres donnant son minimum, ou de les trouver en résolvant des équations. Malheureusement, cette tâche qui semble extrêmement simple s'avère très compliquée dès que le nombre de paramètres augmente. Trouver les paramètres qui optimisent la fonction objectif d'un modèle avec 2 ou 3 paramètres est rapide en résolvant ses équations mathématiquement, mais lorsqu'on se retrouve avec des dizaines, centaines, milliers ou même millions de paramètres, il devient impossible de trouver son minimum optimal en le calculant ou en traçant la fonction, car elle est beaucoup trop compliquée. C'est pourquoi il existe des algorithmes qui vont trouver des paramètres qui minimisent la fonction efficacement, sans devoir la tracer complètement. À la place, on va uniquement l'approximer à quelques endroits, et déterminer uniquement avec ces informations comment modifier les paramètres pour se rapprocher du minimum de la fonction. Pour cette tâche, l'algorithme le plus populaire est l'algorithme du gradient, mais d'autres algorithmes existent également, par exemple la méthode de Newton et l'algorithme génétique.
Algorithme du gradient[modifier | modifier le wikicode]

L'algorithme du gradient ![]() est l'algorithme sur lequel repose la majorité des optimisations de modèles. Il sert à trouver les paramètres qui vont minimiser la fonction objectif en se servant de la dérivée de la fonction. Pour rappel, la dérivée d'une fonction donne la pente de la tangente en chacun de ses points. Donc, un point de la fonction où la dérivée est positive indique que la fonction est en train de monter, et une dérivée négative indique que la fonction descend. Aussi, si la valeur de la dérivée est proche de zéro, la fonction monte ou descend lentement, et si la dérivée est très loin de zéro, la fonction monte ou descend très vite.
est l'algorithme sur lequel repose la majorité des optimisations de modèles. Il sert à trouver les paramètres qui vont minimiser la fonction objectif en se servant de la dérivée de la fonction. Pour rappel, la dérivée d'une fonction donne la pente de la tangente en chacun de ses points. Donc, un point de la fonction où la dérivée est positive indique que la fonction est en train de monter, et une dérivée négative indique que la fonction descend. Aussi, si la valeur de la dérivée est proche de zéro, la fonction monte ou descend lentement, et si la dérivée est très loin de zéro, la fonction monte ou descend très vite.
En apprentissage automatique, on utilise l'algorithme du gradient afin de minimiser la fonction objectif, c'est à dire minimiser l'erreur du modèle entrainé sur les données qu'il utilise durant l'entrainement. Ainsi, le modèle fait de moins en moins d'erreurs et va apprendre. Pour cela, pour chaque exemple du dataset, on calcule la dérivée de la fonction objectif résultante selon les paramètres du modèle, afin d'obtenir la pente de la tangente en chacun des points du dataset. On obtient donc la direction inverse de celle vers laquelle il faut modifier les paramètres du modèle afin d'obtenir une erreur plus petite. On modifie donc les paramètres en faisant un pas dans la direction opposée à celle du gradient. Puis, on recalcule la nouvelle dérivée pour obtenir une nouvelle direction du gradient, on refait un pas dans la direction opposée et ainsi de suite.
Comme on entre ici dans les détails du fonctionnement de l'algorithme du gradient, les concepts deviennent très abstraits. Pour mieux comprendre ce qu'il se passe, on peut considérer l'image à droite. On suppose ici que les isolignes ![]() au centre représentent des hauteurs de plus en plus basses, et la fonction dessinée par ces isolignes est la fonction objectif que l'on cherche à minimiser. Cette fonction est exprimée en fonction des paramètres du modèles, ici nous avons donc 2 paramètres qui ensemble donnent cette fonction objectif. On cherche donc les valeurs des paramètres qui permettent de se retrouver au centre des isolignes. En évaluant la fonction objectif sur le dataset avec le modèle donné, on obtient la valeur du point . On calcule ensuite la dérivée en ce point et on obtient la pente en ce point, qui donne la direction vers laquelle se déplacer pour augmenter la fonction. Comme on cherche à la minimiser, on va faire un pas dans la direction inverse, représenté par la flèche rouge partant du point . On évalue maintenant la fonction objectif en ce nouveau point pour trouver , puis on trouve sa dérivée et fait à nouveau un pas dans la direction inverse, représenté par la flèche rouge partant de . Et on répète l'opération encore plusieurs fois pour s'approcher de plus en plus du minimum.
au centre représentent des hauteurs de plus en plus basses, et la fonction dessinée par ces isolignes est la fonction objectif que l'on cherche à minimiser. Cette fonction est exprimée en fonction des paramètres du modèles, ici nous avons donc 2 paramètres qui ensemble donnent cette fonction objectif. On cherche donc les valeurs des paramètres qui permettent de se retrouver au centre des isolignes. En évaluant la fonction objectif sur le dataset avec le modèle donné, on obtient la valeur du point . On calcule ensuite la dérivée en ce point et on obtient la pente en ce point, qui donne la direction vers laquelle se déplacer pour augmenter la fonction. Comme on cherche à la minimiser, on va faire un pas dans la direction inverse, représenté par la flèche rouge partant du point . On évalue maintenant la fonction objectif en ce nouveau point pour trouver , puis on trouve sa dérivée et fait à nouveau un pas dans la direction inverse, représenté par la flèche rouge partant de . Et on répète l'opération encore plusieurs fois pour s'approcher de plus en plus du minimum.


Autres algorithmes[modifier | modifier le wikicode]
L'algorithme du gradient présenté ci-dessus est l'algorithme le plus couramment utilisé en apprentissage automatique, parce qu'il est simple à implémenter et facilement parallélisable, c'est à dire que son exécution peut se faire sur plusieurs machines (par ex plusieurs CPUs, GPUs ou TPUs, voir même plusieurs ordinateurs) simultanément. Il représente généralement un bon compromis entre la complexité des calculs exécutés et la vitesse de minimisation de la fonction objectif. Cependant, il en existe plusieurs variantes, par exemple l'algorithme du gradient stochastique ou l'algorithme de Frank-Wolfe. L'algorithme du gradient stochastique est la variante la plus fréquemment utilisée.
L'algorithme du gradient et toutes ses variantes sont ce qu'on appelle des algorithmes d'optimisation différentiable. Cela veut dire qu'on utilise la valeur de la fonction et sa dérivée pour l'optimisation. Il existe également des algorithmes qui n'utilisent que la valeur de la fonction, sans sa dérivée, permettant par exemple d'optimiser des fonctions que l'on ne peut pas dériver. C'est le cas par exemple de l'algorithme génétique. Il existe aussi des méthodes qui au contraire utilisent la valeur de la fonction, sa dérivée et sa dérivée seconde ![]() , par exemple la méthode de Newton. Cet algorithme converge plus rapidement car elle utilise plus d'informations pour optimiser ses paramètres, mais elle nécessite aussi beaucoup plus de calculs pour obtenir la dérivée seconde, ce qui la rend moins pratique dans beaucoup d'applications concrètes.
, par exemple la méthode de Newton. Cet algorithme converge plus rapidement car elle utilise plus d'informations pour optimiser ses paramètres, mais elle nécessite aussi beaucoup plus de calculs pour obtenir la dérivée seconde, ce qui la rend moins pratique dans beaucoup d'applications concrètes.
Évaluation[modifier | modifier le wikicode]

La phase d'évaluation permet de tester le modèle afin de déterminer s'il est bon ou mauvais selon des critères définis. Pour cela, il faut premièrement une métrique qui indiquera un niveau de performance ou la proportion d'erreurs. On utilisera souvent la même fonction que celle qu'on utilise pour calculer l'erreur lors de l'apprentissage, bien qu'il arrive parfois qu'on en utilise une autre pour l'évaluation. Deuxièmement, il faut un nouveau jeu de données que le modèle n'a jamais vu. En effet, il est important de tester le modèle sur des données qui n'ont pas été utilisées pour l'entrainer, car on veut aussi détecter si le modèle a fait du surapprentissage en apprenant les données « par cœur ». Comme on a rarement plusieurs jeux de données différents sous la main, une pratique courante est de séparer le jeu de donnée qu'on a en deux parties et d'utiliser l'une pour l'entrainement et l'autre pour l'évaluation. Il faut toutefois se souvenir que chaque jeu de donnée est susceptible de contenir des biais et qu'il peut être très bénéfique d'également tester son modèle avec d'autres jeux de données complètement différents pour découvrir et limiter ces biais.
Le test du modèle est très simple: on donne le nouveau jeu de données au modèle afin qu'il fasse des prédictions pour chaque exemple. Ensuite, on compare les prédictions aux vrais labels des exemples et on calcule l'erreur, donc la performance du modèle, en utilisant la métrique choisie.
Certaines évaluations plus poussées peuvent également chercher à tromper le modèle exprès en lui donnant des exemples qui vont viser à exploiter ses faiblesses, que l'on appelle en anglais adversarial examples ![]() 7. Faire ça permet de tester la robustesse du modèle, donc sa performance sur des exemples en conditions dégradées. Par exemple, on peut tenter de donner des images bruitées
7. Faire ça permet de tester la robustesse du modèle, donc sa performance sur des exemples en conditions dégradées. Par exemple, on peut tenter de donner des images bruitées ![]() à un modèle et voir s'il est encore capable d'identifier ce que l'image contient. On peut aussi donner des exemples qui ont été optimisés afin de tromper le modèle au maximum. Selon l'objectif d'utilisation du modèle, il peut s'avérer très important de faire ce genre tests poussés. Par exemple, si une voiture autonome utilise les images d'une caméra pour repérer et interpréter les panneaux routiers, le modèle qui fait ces interprétations doit continuer à correctement lire les panneaux lorsqu'il pleut ou bien que le panneau est sale8.
à un modèle et voir s'il est encore capable d'identifier ce que l'image contient. On peut aussi donner des exemples qui ont été optimisés afin de tromper le modèle au maximum. Selon l'objectif d'utilisation du modèle, il peut s'avérer très important de faire ce genre tests poussés. Par exemple, si une voiture autonome utilise les images d'une caméra pour repérer et interpréter les panneaux routiers, le modèle qui fait ces interprétations doit continuer à correctement lire les panneaux lorsqu'il pleut ou bien que le panneau est sale8.
Enjeux et limites[modifier | modifier le wikicode]
Données[modifier | modifier le wikicode]
Les modèles entrainés par apprentissage automatique sont extrêmement dépendants des données utilisées pour leur entrainement. Si les données sont insuffisantes ou imprécises, le modèle sera mauvais. Si les données sont biaisées, le modèle sera biaisé9. Et ainsi de suite. Cela pose un véritable challenge pour les chercheurs et travailleurs dans le domaine, car obtenir de grandes quantités de données est souvent difficile, et il n'existe pas de méthode universelle qui permettra de s'assurer de la qualité des données utilisées. Lors du pré-traitement, les données sont déjà nettoyées, mais c'est largement insuffisant pour garantir des données de qualité en quantité suffisante. En voici quelques raisons:
- Combien de données sont suffisantes pour entrainer un bon modèle? Cela va dépendre d'énormément de facteurs tels que le type de tâche et le type de modèle. En règle général, plus il y a de données, mieux le modèle obtenu sera, mais d'autres problèmes surviennent lorsqu'on travaille avec de grandes quantités de données. Notamment, utiliser énormément de données nécessite énormément de puissance de calcul, ce qui est coûteux à la fois en termes de matériel et d'un point de vue environnemental. Il s'agit donc de trouver un compromis adéquat entre la quantité de données (la complexité du modèle entrainé jouera également un rôle important) et les ressources utilisées pour entrainer le modèle.
- Qu'est-ce qui définit la qualité de données? On peut par exemple souhaiter réduire le biais dans les données, c'est-à-dire s'assurer que les données représentent toute la diversité existante. Par exemple, on peut fixer l'objectif d'avoir autant d'hommes que de femmes dans les exemples, et que toutes les ethnies soient représentées significativement
 10. Ainsi, le modèle entrainé fonctionnera sur tout type d'exemple, ce qui réduit le surapprentissage . Mais on souhaite également que ces facteurs de diversité ne corrèlent pas sans raison avec les labels, c'est-à-dire qu'on veut éviter les stéréotypes dans les données11. Par exemple, on ne veut pas que dans les données, 80% des infirmiers soient des femmes et 80% des médecins soient des hommes, car ça correspond à un stéréotype indésirable que le modèle apprendra sans aucun doute s'il est entrainé avec ces données biaisées12. De telles correlations indésirables sont souvent dues à des facteurs de confusion. Naturellement, il existe également ce genre de facteurs de confusion entre des attributs différents que ceux liés à la diversité, et ils sont généralement tout aussi indésirables.
10. Ainsi, le modèle entrainé fonctionnera sur tout type d'exemple, ce qui réduit le surapprentissage . Mais on souhaite également que ces facteurs de diversité ne corrèlent pas sans raison avec les labels, c'est-à-dire qu'on veut éviter les stéréotypes dans les données11. Par exemple, on ne veut pas que dans les données, 80% des infirmiers soient des femmes et 80% des médecins soient des hommes, car ça correspond à un stéréotype indésirable que le modèle apprendra sans aucun doute s'il est entrainé avec ces données biaisées12. De telles correlations indésirables sont souvent dues à des facteurs de confusion. Naturellement, il existe également ce genre de facteurs de confusion entre des attributs différents que ceux liés à la diversité, et ils sont généralement tout aussi indésirables.
Ceci ne sont que quelques problèmes liés aux données parmi beaucoup d'autres qui peuvent survenir. Il existe tout un domaine de recherche, la science des données, qui se consacre en grande partie à cette question et permet d'apporter quelques solutions pour améliorer la qualité des données utilisées. Cela dit, lorsqu'on travaille dans le domaine de l'apprentissage automatique, et simplement lorsqu'on est confronté à l'utilisation de modèles, il est essentiel de connaître les enjeux liés aux données et les problèmes qu'ils peuvent causer chez les modèles entrainés dessus, afin de pouvoir comprendre mieux d'où viennent les prédictions du modèle13.
Modèles[modifier | modifier le wikicode]
Il existe une multitude d'enjeux liés au type de modèles entrainés. L'un des plus importants est le problème de l'explicabilité des modèles. La plupart du temps, en apprentissage automatique, on choisit un type de représentation mathématique, donc un modèle, puis on l'entraine. Avec l'évaluation, on obtient une bonne idée de la qualité du modèle obtenu, mais cela ne répond en aucun cas à des questions du style:
- « Pour quelle raison le modèle fait-il ces prédictions? Quels sont ses arguments? Sont-ils valides? »
- « Pourquoi utiliser ce modèle et non un autre? Est-ce qu'un autre modèle serait également adapté pour résoudre la même tâche? Pourquoi? »
- « Quels sont les points faibles du modèle? Est-ce qu'il contient des biais? » (Cette question rejoint partiellement les problèmes liés aux données présentés ci-dessus)
Un domaine récent de l'apprentissage automatique, nommé Explainable AI ![]() ou Interpretable AI
ou Interpretable AI ![]() , a émergé afin de tenter de répondre à ce genre de questions, car il est essentiel de comprendre les raisons qui poussent un système d'intelligence artificielle à prendre ses décisions. En effet, par exemple, si un modèle prédit qu'une radiographie qu'on lui donne contient un cancer, il est essentiel de pouvoir vérifier que le modèle a regardé au bon endroit de l'image pour arriver à cette conclusion. Ce genre de choses nous semblent évidentes en tant qu'humains, mais les machines ne raisonnent pas comme des humains. Ainsi, il arrive qu'on entraine un modèle à distinguer un loup d'un chien, et que le modèle base sa prédiction sur la présence de neige sur la photo en prédisant « loup » quand il y a de la neige sur l'image et « chien » s'il n'y en a pas14. Ce genre de raisonnement est totalement erroné, mais il peut donner de bons résultats lors de l'entrainement et de l'évaluation si la plupart des photos de loup contiennent de la neige et la plupart des photos de chien n'en ont pas. Souvent, le modèle ne nous dit que « loup » ou « chien » sans donner d'explication, il faut donc trouver des moyens de trouver la raison de cette prédiction par nous-même et vérifier si les arguments menant à cette prédiction font sens. Ceci n'est qu'un exemple pour illustrer le problème, il existe évidemment beaucoup d'applications où comprendre les décisions d'un modèle est essentiel, un autre exemple étant les voitures autonomes.
, a émergé afin de tenter de répondre à ce genre de questions, car il est essentiel de comprendre les raisons qui poussent un système d'intelligence artificielle à prendre ses décisions. En effet, par exemple, si un modèle prédit qu'une radiographie qu'on lui donne contient un cancer, il est essentiel de pouvoir vérifier que le modèle a regardé au bon endroit de l'image pour arriver à cette conclusion. Ce genre de choses nous semblent évidentes en tant qu'humains, mais les machines ne raisonnent pas comme des humains. Ainsi, il arrive qu'on entraine un modèle à distinguer un loup d'un chien, et que le modèle base sa prédiction sur la présence de neige sur la photo en prédisant « loup » quand il y a de la neige sur l'image et « chien » s'il n'y en a pas14. Ce genre de raisonnement est totalement erroné, mais il peut donner de bons résultats lors de l'entrainement et de l'évaluation si la plupart des photos de loup contiennent de la neige et la plupart des photos de chien n'en ont pas. Souvent, le modèle ne nous dit que « loup » ou « chien » sans donner d'explication, il faut donc trouver des moyens de trouver la raison de cette prédiction par nous-même et vérifier si les arguments menant à cette prédiction font sens. Ceci n'est qu'un exemple pour illustrer le problème, il existe évidemment beaucoup d'applications où comprendre les décisions d'un modèle est essentiel, un autre exemple étant les voitures autonomes.
Sécurité dans l'apprentissage automatique[modifier | modifier le wikicode]
Vikiliens pour compléter[modifier | modifier le wikicode]
Références[modifier | modifier le wikicode]
- ↑ 1,0 et 1,1 http://archive.ics.uci.edu/ml/datasets/Iris
- ↑ Jeu de données utilisé dans l'image: https://www.kaggle.com/mustafaali96/weight-height
- ↑ https://thispersondoesnotexist.com/
- ↑ https://microsoft.github.io/FaceSynthetics/
- ↑ https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9053146
- ↑ https://towardsdatascience.com/all-machine-learning-models-explained-in-6-minutes-9fe30ff6776a
- ↑ https://towardsdatascience.com/adversarial-examples-in-deep-learning-be0b08a94953
- ↑ https://spectrum.ieee.org/slight-street-sign-modifications-can-fool-machine-learning-algorithms
- ↑ https://www.flawedfacedata.com/
- ↑ http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf
- ↑ https://www.vice.com/en/article/qkqwxp/that-viral-faceapp-is-making-everyone-look-whiter
- ↑ https://algorithmwatch.org/en/google-translate-gender-bias/
- ↑ https://fairmlbook.org/pdf/fairmlbook.pdf
- ↑ https://arxiv.org/pdf/1602.04938.pdf
Sources additionnelles[modifier | modifier le wikicode]
- L'apprentissage par renforcement sur Towards Data Science
- Présentation de modèles d'apprentissage automatique sur Towards Data Science
|